code snippets, tutorials, and data tips here
finding time to code outside of work is tough but I will try my best to keep this space alive.

|
Last year, I helped a friend with his job search in Singapore by scraping companies' reviews from Glassdoor using Python. The script is quite simple but it requires some maintenance efforts to update as the HTML content of Glassdoor web pages changes all the time. In fact, I had to make a few modifications when I tried to run it recently. I used to be able to easily extract companies' Glassdoor sub-ratings such as Recommend, CEO Approval, and Business Outlook - but, at the time of writing, it has been more complex to do so.
Nevertheless, I'll share with you how to do it in this post (the script still works as of 8 September 2021). Hope you'd find it useful! Before we go into the script, there's a quicker way to bypass the login block and read multiple Glassdoor webpages
Glassdoor would allow you to view only a few webpages if you don't have a valid login. To bypass this, simply copy-paste the URL and open it in a new incognito window on your web browser. This method would be perfect if you only have a few pages to read through (writing a script to scrape the content would be a bit overkill).
But... if you need to read through A LOT of web pages or want to collect the data for analysis, then continue reading. What you will need
What's in the script
You can find my script on Google Colab at this link. I'll explain the key components of the script below.
1. Load the required python libraries
#import the libraries import os import time import numpy as np import pandas as pd import math from bs4 import BeautifulSoup from urllib.request import Request, urlopen
2. Create a function to scrape any Glassdoor company review web page This function takes in a web page URL and extracts the content for the company's reviews. We will use this function in the for loop later to scrape multiple web pages. Disclaimer: the script might not work or will return empty if there are any changes to the HTML structure of the page. Do inspect the web page HTML elements and modify the script accordingly. #create a function to scrape any Glassdoor company review page #the code still works when I run it on 7 Sep, 2021, but the html content of Glassdoor webpages changes all the time #please inspect the webpage and make the necessary changes to the html tags if any of the list returns empty def review_scraper(url): #scraping the web page content hdr = {'User-Agent': 'Mozilla/5.0'} req = Request(url,headers=hdr) page = urlopen(req) soup = BeautifulSoup(page, "html.parser") #define some lists Summary=[] Date_n_JobTitle=[] Date=[] JobTitle=[] AuthorLocation=[] OverallRating=[] Pros=[] Cons=[] #get the Summary for x in soup.find_all('h2', {'class':'mb-xxsm mt-0 css-5j5djr'}): Summary.append(x.text) #get the Posted Date and Job Title for x in soup.find_all('span', {'class':'authorJobTitle middle common__EiReviewDetailsStyle__newGrey'}): Date_n_JobTitle.append(x.text) #get the Posted Date for x in Date_n_JobTitle: Date.append(x.split(' -')[0]) #get Job Title for x in Date_n_JobTitle: JobTitle.append(x.split(' -')[1]) #get Author Location for x in soup.find_all('span', {'class':'authorLocation'}): AuthorLocation.append(x.text) #get Overall Rating for x in soup.find_all('span', {'class':'ratingNumber mr-xsm'}): OverallRating.append(float(x.text)) #get Pros for x in soup.find_all('span', {'data-test':'pros'}): Pros.append(x.text) #get Cons for x in soup.find_all('span', {'data-test':'cons'}): Cons.append(x.text) #putting everything together Reviews = pd.DataFrame(list(zip(Summary, Date, JobTitle, AuthorLocation, OverallRating, Pros, Cons)), columns = ['Summary', 'Date', 'JobTitle', 'AuthorLocation', 'OverallRating', 'Pros', 'Cons']) return Reviews 3. Make a for loop, add your starting URL and start scraping! In this snippet, I used the URL to Boston Consulting Group's Glassdoor review page as an example and set the max number of pages to 5 to save time. Do make the necessary modification to the script as required. #paste/replace the url to the first page of the company's Glassdoor review in between the "" input_url="https://www.glassdoor.sg/Reviews/Boston-Consulting-Group-Reviews-E3879" #scraping the first page content hdr = {'User-Agent': 'Mozilla/5.0'} req = Request(input_url+str(1)+".htm?sort.sortType=RD&sort.ascending=false",headers=hdr) page = urlopen(req) soup = BeautifulSoup(page, "html.parser") #check the total number of reviews countReviews = soup.find('div', {'data-test':'pagination-footer-text'}).text countReviews = float(countReviews.split(' Reviews')[0].split('of ')[1].replace(',','')) #calculate the max number of pages (assuming 10 reviews a page) countPages = math.ceil(countReviews/10) countPages #I'm setting the max pages to scrape to 3 here to save time maxPage = 3 + 1 #uncomment the line below to set the max page to scrape (based on total number of reviews) #maxPage = countPages + 1 #scraping multiple pages of company glassdoor review output = review_scraper(input_url+str(1)+".htm?sort.sortType=RD&sort.ascending=false") for x in range(2,maxPage): url = input_url+"_P"+str(x)+".htm?sort.sortType=RD&sort.ascending=false" output = output.append(review_scraper(url), ignore_index=True) #display the output display(output) And Done! the script should give you a dataframe that looks like this. 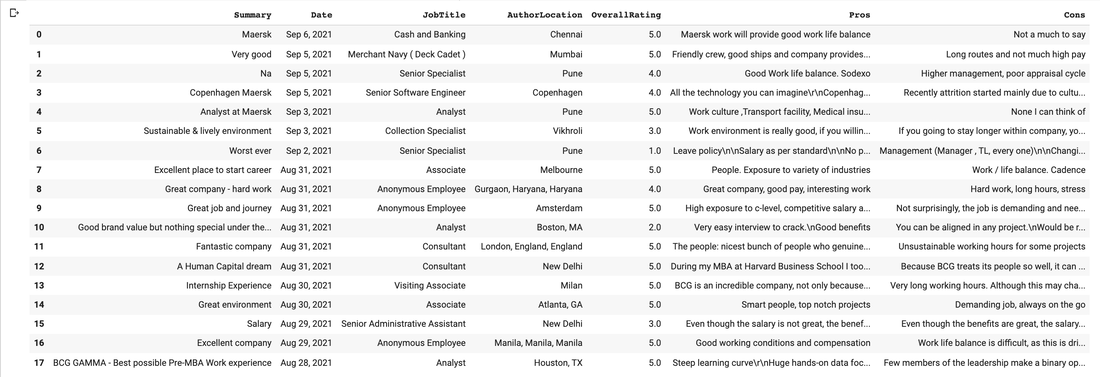
Final words
The script also works if the company has offices in multiple countries and you want the reviews for a particular country's office. You just need to paste in the specific URL. For instance, the URL for BCG Singapore's Glassdoor reviews is different from that for BCG Global.
Once you have gotten the hang of it, it should be quite straightforward to scrape other information from Glassdoor, such as the average pay by job title or job listings. I hope you find this useful for your job search, data analysis work, or just for your own learning :) You can view the full script on my Google Colab too. Link below. Cheers!
6 Comments
Sandeep
5/15/2022 05:12:54 am
I tried running your Colab as is; doesn't seem to return results now. Do you think the code needs to be updated?
Monica
1/24/2024 01:22:34 pm
Looks like they updated their robots.txt aka the rules of webscraping that they disallow /reviews/ this code worked for me in Sept 2022
not.a.bot
6/22/2023 10:36:12 am
Wow...thanks so much. Very helpful! :) Leave a Reply. |

Categories
All
Feature Posts
Tableau Time Series Chart

Trump's Tweet Cloud

Confusion Matrix Explained
Martin Scorsese's Actors
Archives
August 2023
|
